
31.07.2020, Vladimír Klaus, navštíveno 3238x
Statistika indexů, tak jak ji získáme níže uvedeným skriptem, nám umožní především posoudit, jak jsou indexy fragmentované. Protože pokud jsou fragmentované hodně, je třeba s tím něco udělat, neb to má nebo může mít dost zásadní vliv na výkon databáze – rychlost hledání apod.
Indexů je více druhů (Clustered, Nonclustered, Heap), ale můžete mít i fulltextový index/katalog. To ale není v tuto chvíli podstatné. Ostatně to, zda se s indexem bude něco provádět, záleží výhradně na oné fragmentaci.
Normální indexy
Takto vypadá statistika indexů u jedné databáze a vidíte, že u řady indexů je fragmentace opravdu velká a není od věci tuto situaci řešit již ve chvíli, kdy je hodnota větší než 10 %.
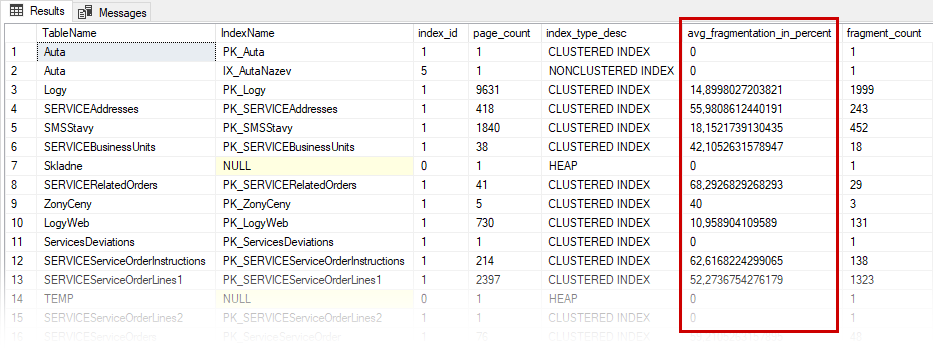
Tak nejprve skript, kterým získáte tuto statistiku:
SELECT
OBJECT_NAME(A.[object_id]) as 'TableName',
B.[name] as 'IndexName',
A.[index_id],
A.[page_count],
A.[index_type_desc],
A.[avg_fragmentation_in_percent],
A.[fragment_count]
FROM
sys.dm_db_index_physical_stats(db_id(),NULL,NULL,NULL,'LIMITED') A INNER JOIN
sys.indexes B ON A.[object_id] = B.[object_id] and A.index_id = B.index_idPřípadně ještě druhý, který byl ale měl dávat stejné výsledky:
SELECT dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
dbindexes.[Type_Desc] as 'Type',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID() AND dbtables.[name] like '%%'
ORDER BY indexstats.avg_fragmentation_in_percent descA platí jednoduché pravidlo:
- pokud je fragmentace menší než 10 %, tak se nemusí dělat nic
- pokud je fragmentace 10 – 30 %, pak by se měla provést operace REORGANIZE
- a pokud je větší než 30 %, pak operace REBUILD
SQL příkaz pak vypadá takto:
ALTER INDEX PK_Logy ON Logy REORGANIZE
-- resp.
ALTER INDEX PK_ServiceService ON SERVICEServices REBUILD
- REORGANIZE - rychlejší, index stále existuje, jen se optimalizuje
- REBUILD - pomalejší, náročnější, index v tu chvíli není dostupný – tvoří se celý znovu
Když si poté necháte vygenerovat statistiku, je situace výrazně lepší. Zároveň ale nesmíte očekávat, že budou všude nuly. ;-)
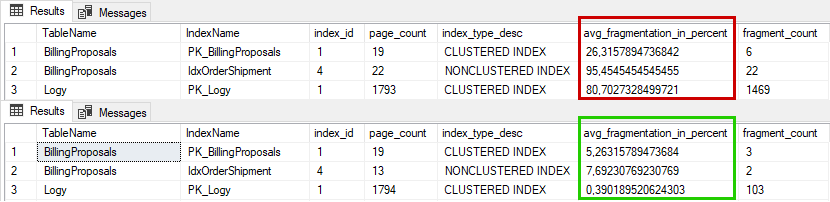
A protože ve větší databázi bývá zpravidla poměrně velké množství indexů, je vhodné celou operaci trochu zautomatizovat. Tedy jednak si pro statistiku udělat uloženou proceduru, pak ji jednou za čas zavolat, nějakým cyklem procházet a volat jednotlivé optimalizace indexů dle zjištěné fragmentace.
Fulltextový index/katalog
Pro statistiku fulltextových indexů se používá trochu jiný skript, ale princip je totožný – opět se dle fragmentace řeší, co se s indexem má udělat.
SELECT c.fulltext_catalog_id, c.name AS fulltext_catalog_name, i.change_tracking_state,
i.object_id, OBJECT_SCHEMA_NAME(i.object_id) + '.' + OBJECT_NAME(i.object_id) AS object_name,
f.num_fragments, f.fulltext_mb, f.largest_fragment_mb,
100.0 * (f.fulltext_mb - f.largest_fragment_mb) / NULLIF(f.fulltext_mb, 0)
AS fulltext_fragmentation_in_percent
FROM sys.fulltext_catalogs c
JOIN sys.fulltext_indexes i
ON i.fulltext_catalog_id = c.fulltext_catalog_id
JOIN (
-- Compute fragment data for each table with a full-text index
SELECT table_id,
COUNT(*) AS num_fragments,
CONVERT(DECIMAL(9,2), SUM(data_size/(1024.*1024.))) AS fulltext_mb,
CONVERT(DECIMAL(9,2), MAX(data_size/(1024.*1024.))) AS largest_fragment_mb
FROM sys.fulltext_index_fragments
GROUP BY table_id
) f
ON f.table_id = i.object_id
Zde je tedy jen jeden záznam a fragmentace vyžadující REORGANIZE.

S ohledem na to, že fulltextové hledání je většinou extrémně rychlé i při horší fragmentaci, tuto optimalizaci dělám třeba jen občas a nebo vůbec neřeším statistiku a vždy udělám REBUILD:
ALTER FULLTEXT CATALOG fcZasilky REBUILD WITH ACCENT_SENSITIVITY=OFFJak vyplývá nejen z níže uvedených zdrojů, problematika indexů není úplně jednoduchá, panují na to i různé názory (např. že hranice není 30, ale 40 %) apod. Takže pokud by "moje" jednoduché řešení s výkonem nepomohlo, je třeba se ponořit do problematiky hlouběji. Je možné, že vám chybí další indexy nebo máte ne úplně optimálně zvolené datové typy atd.
Zdroje: